CSN & cCSN & PC
CSN
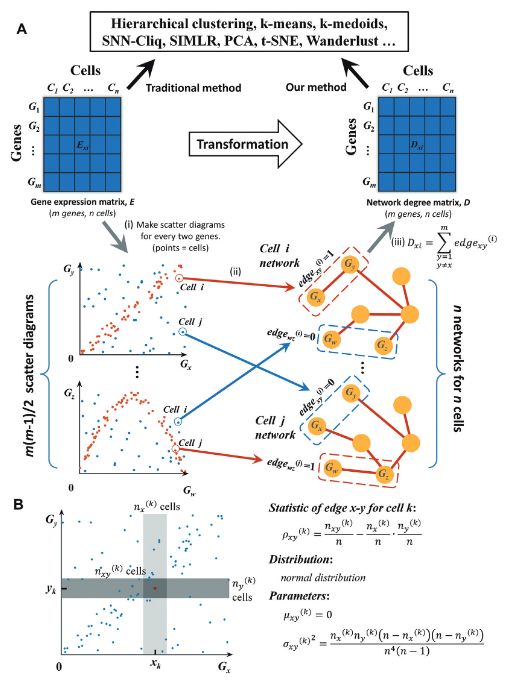
文章提出了一种基于统计依赖性的计算方法来构建每个细胞的基因-基因网络。
- 对于每对基因
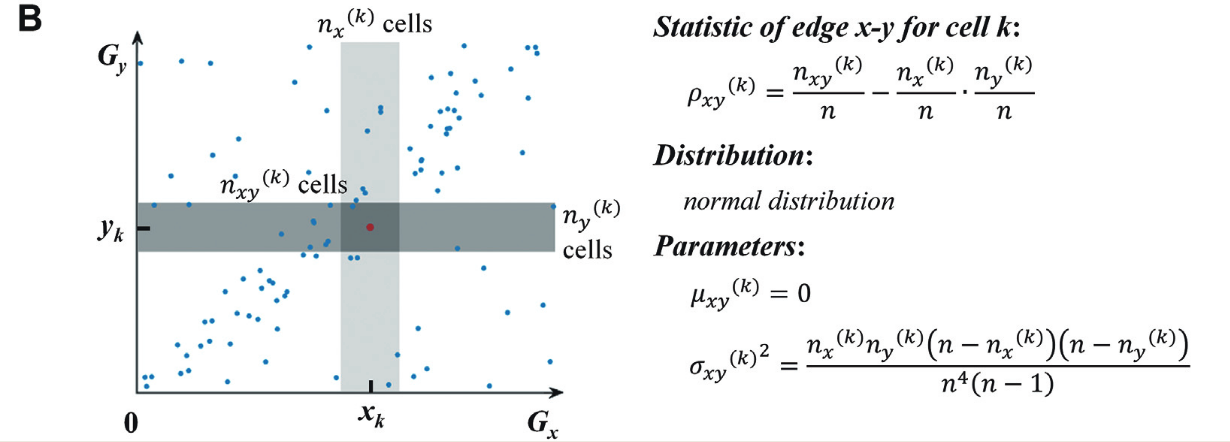
和 ,定义一个新的统计量 ,用于度量它们在单个细胞 中的独立性。这一统计量的计算过程基于概率的频率估算,具体步骤包括: - 计算每个基因的边缘频率
和 ,这两者分别是基因 和基因 在细胞 中的表达频率。 - 计算基因对
在细胞 中的联合频率 。
- 计算每个基因的边缘频率
通过以下公式来估算这些概率:
边缘概率估算:
其中,
可以得到每个细胞中基因对的独立性统计量
PC
PC 算法的主要步骤如下:
初始化阶段:首先,PC 算法假设所有的变量之间都有边相连,即它开始时认为每对变量之间都有可能存在直接的因果关系。
独立性检验:然后,PC 算法通过对每对变量之间进行条件独立性检验来逐步删除图中的边。具体地,算法使用统计检验(如假设检验)来判断在控制其他变量的情况下,两个变量是否独立。如果独立,则表示这两个变量之间没有直接的因果关系,算法将删除该边。主要修改这部分代码
逐步删除边:PC 算法采用逐步消除的策略,首先检测一对变量之间的边,然后逐渐增加控制的变量集合,直到无法进一步简化图结构。
有向边与无向边:在完成边的删除后,PC 算法通过确定变量之间的条件独立性来确定哪些边应该是有向边。这个阶段通常需要额外的步骤来确定方向性,通常依赖于启发式规则和额外的假设(例如,假设数据来自于一个“真实”因果过程)。
生成因果图:最后,PC 算法会输出一个因果结构图,图中的边表示变量之间可能的因果关系。
独立性检验
独立性
两个随机变量
换句话说,
条件独立性
条件独立性表示,在给定一个或多个变量的条件下,两个变量独立。用数学公式表示,如果给定了一个变量集合
这意味着,在已知
即,条件独立性意味着,在条件
贝叶斯定理
贝叶斯定理可以用以下公式表示:
其中:
:在事件 已经发生的条件下,事件 发生的条件概率(后验概率)。 :在事件 已经发生的条件下,事件 发生的条件概率(似然函数)。 :事件 发生的先验概率,表示在没有任何证据的情况下,事件 发生的概率。 :事件 发生的总概率,可以通过全概率公式计算得到。
c-CSN
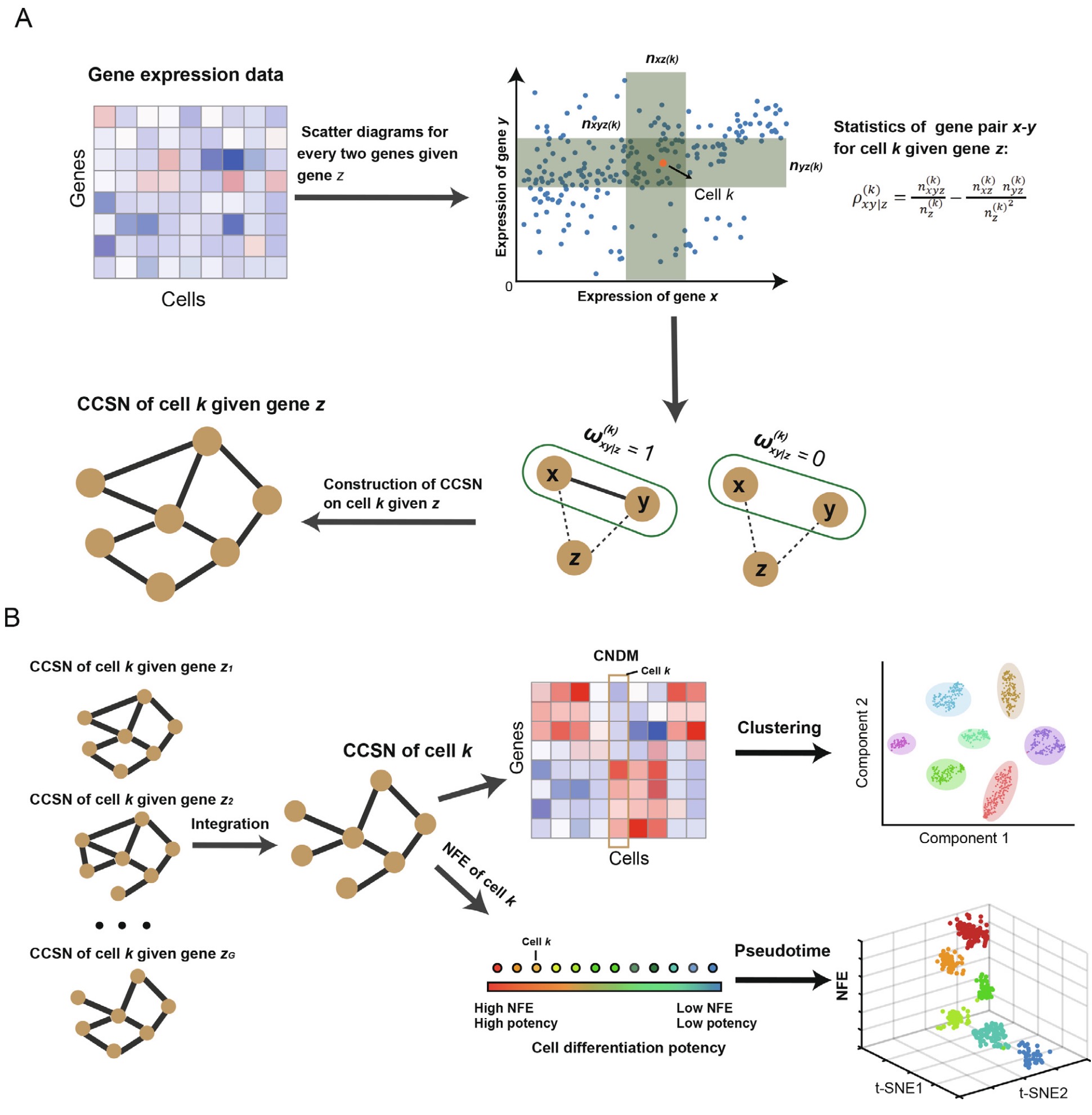
x, y 表示进行独立性检验的两个基因,Z 表示一个集合
根据条件独立性的定义